
Figure 1. Technique used to convert synthetic dataset to be used in training.
Max Maton, Jan van Gemert, Miriam Huijser, Osman Kayhan
Creating big datasets is often difficult or expensive which causes people to augment their dataset with rendered images. This often fails to significantly improve accuracy due to a difference in distribution between real and rendered datasets. This paper shows that the gap between synthetic and real-world image distributions can be closed by using GANs to convert the synthetic data to a dataset which has the same distribution as the real data. Training this GAN requires only a fraction of the dataset traditionally required to get a high classification accuracy. This converted data can subsequently be used to train a classifier with a higher accuracy than a classifier trained only on the real dataset.
Deep learning has revolutionised visual object recognition. Thanks to huge datasets and fast hardware (GPUs), current object recognition approaches have near-human accuracy.
Because creating big datasets is often very expensive, start to turn to rendered images to augment their datasets. However, training networks on rendered images may not achieve the desired accuracy due to a gap between synthetic and real image distributions.
Another development in current research is the increased focus on Generative Adversarial Networks (GANs) to generate images that look similar to the images they were trained on.
In this paper the impact of the distribution gap between synthetic and real image distributions is decreased by using a GAN to modify rendered images to have the same distribution as real images. This technique is shown to be useful for inflating very small datasets to a level where they can be used to create more accurate classifiers.
Rendered data can sometimes be used to train networks, i.e. using rendered images to segment images of indoor scenes, font character classification trained on interpolated real samples and facial expression analysis using rendered faces. These networks are trained by creating a rendered dataset that is as close as possible in statistical distribution as the real dataset. Generally this is very difficult or expensive to achieve.
The problem of creating rendered datasets with a distribution close to a real dataset can be solved by using domain adaptation. This is generally done using Generative Adversarial Networks [1, 2, 3] trained to create samples based on images in the rendered dataset that are indistinguisable from images in the real dataset. We decided to perform this research on the GAN as described by Bousmalis et al due to the available TensorFlow implementation.

The basis of this research is a GAN that converts images from a rendered dataset distribution to an image that appears to come from the distribution of a real dataset. This GAN consists of three parts which are shown in figure _. The first part is a generator network that does the image conversion. The second part of the GAN is a discriminator, which tries to distinguish between the output of the generator and images from the real dataset. The third part of the GAN is a classifier that predicts the label of images coming from either the real dataset, the generator or the rendered dataset. All these networks are trained in parallel. The discriminator and classifier are trained to reduce the amount of misclassifications. The generator is trained to minimise the amount of pixels changed in the image, to minimise the loss in classification by the classifier and to try to fool the discriminator to classify the image as real.
To test the effects of inflating datasets when using this technique, we first trained the GAN with a real and rendered dataset. We then apply the trained GAN on the rendered dataset to create a new synthetic dataset. A combined dataset consisting of the synthetic dataset and the real dataset was used to train a second classifier.
We evaluated this technique on the MNIST dataset together with a rendered dataset generated by rendering open source font digits in multiple rotations for all number classes.
The synthetic dataset contains samples from 149 fonts, with each digit rendered having 47 variations each with a distinct rotation between -47 and 46 degrees. All images were normalised using the same algorithm used to normalise the MNIST samples. A random sample of 10,030 of those images were put in a test set and the remaining 60,000 images were used as the rendered dataset.
The GAN was modified to use 10% of the training data as a validation set instead of a constant 1,000 samples as this allowed for smaller sample sizes.
For multiple ratios r, where 0 < r < 1, we created the following datasets:
60,000 * r images from the original MNIST dataset.60,000 * (1 - r) images from the rendered font dataset.We used these two datasets to train the GAN using 375,000 steps with batchsize 32 and subsequently applied the trained GAN on the MNISTfont dataset to create the MNISTGAN dataset. This made the MNISTGAN dataset have the exact same size as MNISTfont.
With these datasets we trained five instances of the following classifiers:
Each classifier was tested on the MNIST test set which resulted in an classification accuracy.
r = 0.001 - top is from MNISTfont, bottom is the generated image in MNISTGAN.









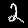
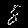

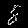






r = 0.007 - top is from MNISTfont, bottom is the generated image in MNISTGAN.


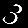







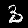
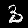
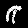




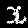

r = 0.100 - top is from MNISTfont, bottom is the generated image in MNISTGAN.
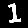

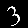















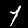
r = 0.700 - top is from MNISTfont, bottom is the generated image in MNISTGAN.

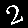
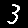










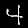
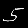



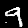
To validate whether the GAN was creating useful images, we looked at the resulting images in MNISTGAN:
From visual inspection it is apparent that the GAN has trouble keeping the labels consistent if there is not enough real training data. An example of this are the 1 and the 2 of r = 0.007 in figure 3: they both result in something that looks like the same 8 instead of something that looks like a 1 or 2 respectively. This means that the classifier trained on this new dataset will receive two very similar samples with conflicting labels. We measured the accuracy on MNIST of C-MNISTGAN and found low accuracy for lower ratios. This supports the conclusion that there is an issue with labeling when the GAN is not trained with enough real data.
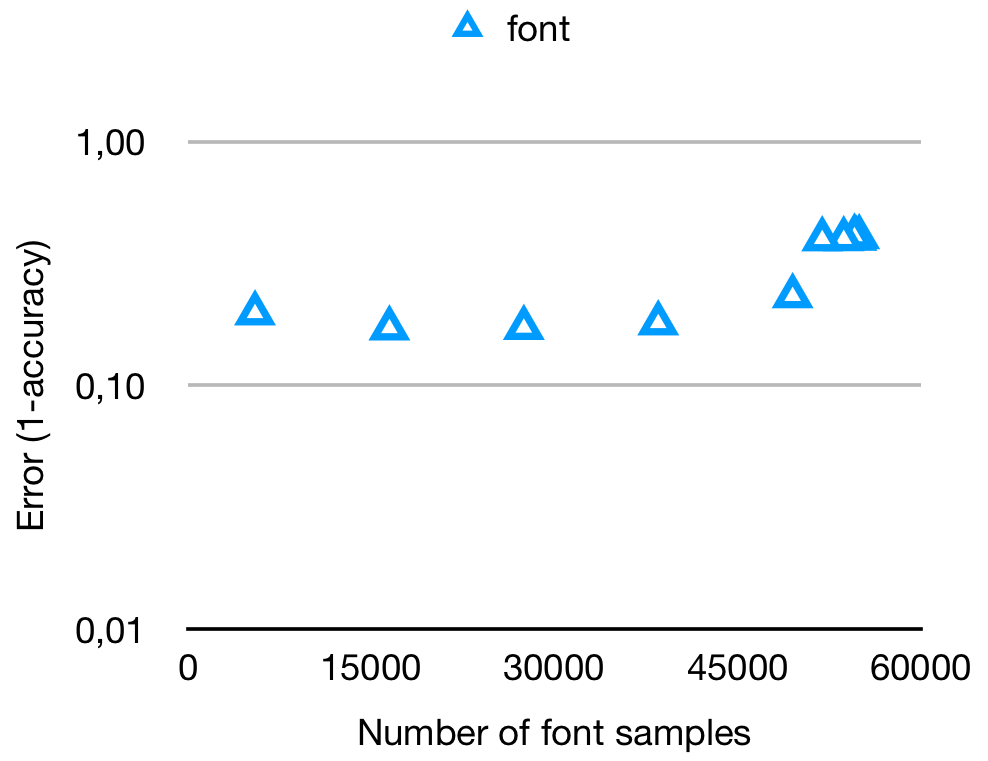
To make sure we actually test whether the GAN is able to close the distribution gap we looked at the accuracy of C-MNISTfont. For this dataset the error shows an inverse relation between the amount of samples and the performance of the classifier, which can be seen in figure 4. This indicates that a gap exists between the rendered font dataset and the MNIST test dataset.
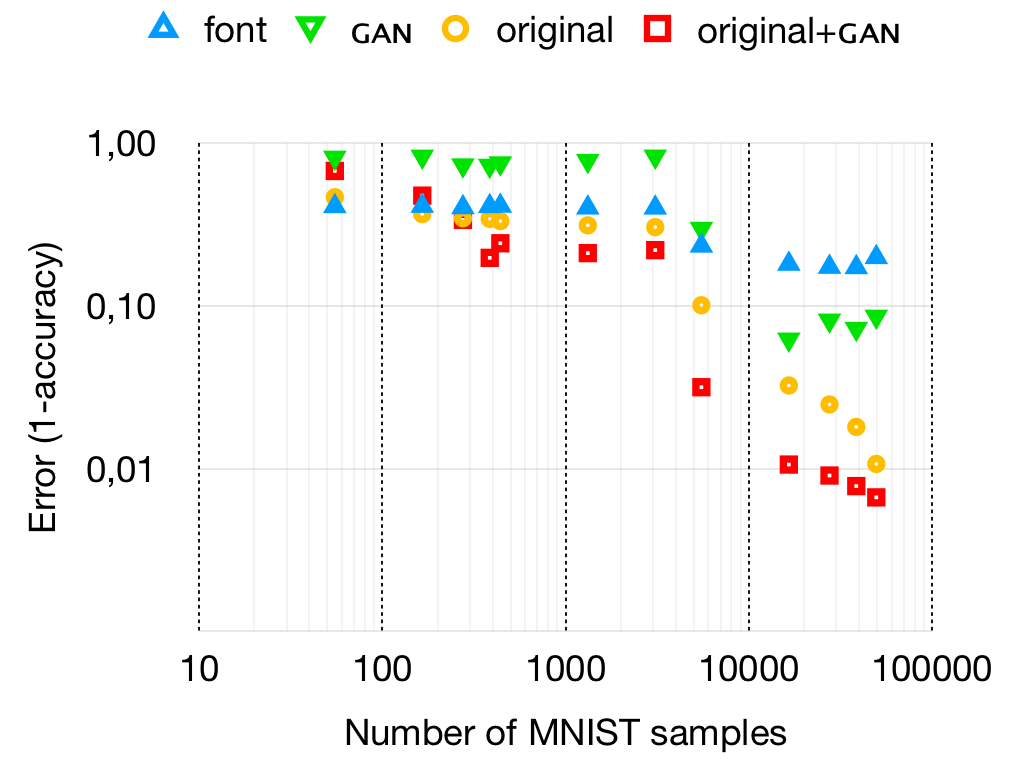
We compared the accuracy of C-MNISTfont, C-MNISTGAN, C-MNISToriginal and C-MNISToriginal+GAN to see whether training with the MNISToriginal+GAN dataset is better than training with one of the individual datasets. The result of this comparison can be seen in figure 5.
C-MNISToriginal+GAN is only more accurate than the C-MNISToriginal when the GAN is trained on more than 385 real images (r = 0.007). There seems to be a minimum amount of real samples after which the GAN starts to produce meaningful data.
Using MNIST as a test case, this technique is able to close the distribution gap even with as little 0.7% real data in the resulting dataset.
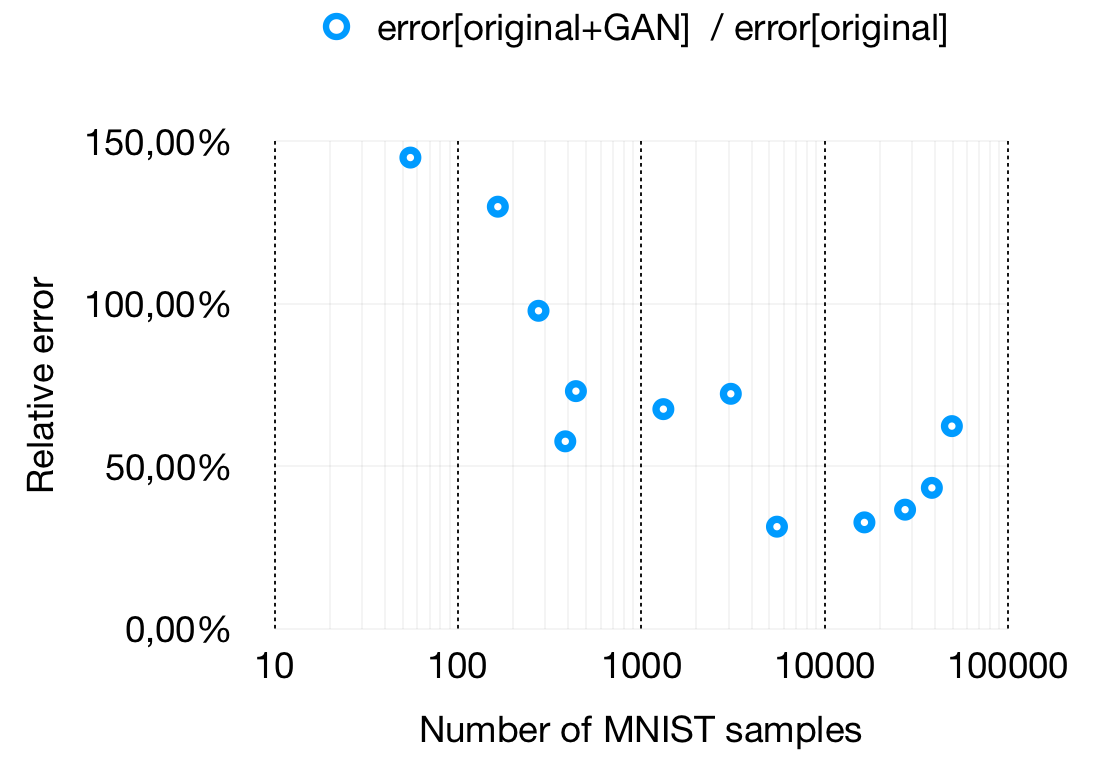
We also compared the difference in wrong predictions between C-MNISToriginal and C-MNISToriginal+GAN. As is shown in figure _, the highest reduction in error was achieved with 5,500 MNIST images and 49,500 font images. This indicates that for MNIST, this technique becomes more effective when the ratio between real and rendered images becomes less extreme.
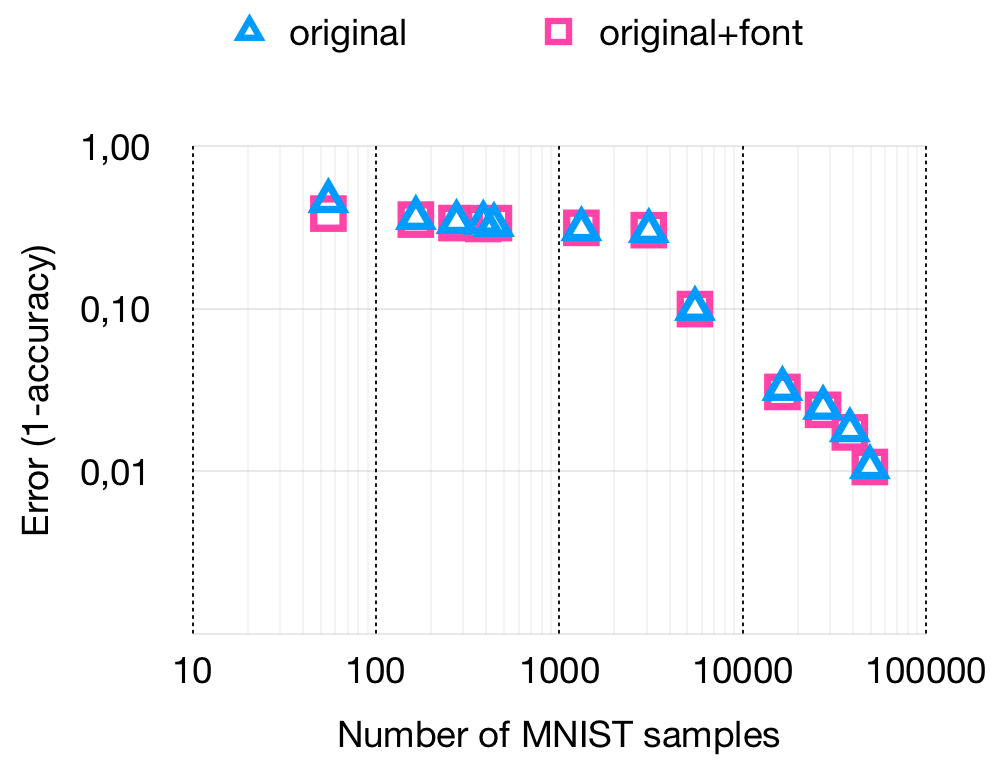
To confirm that the improved results of C-MNISToriginal+GAN can not be solely explained by the addition of the rendered font data, we compared C-MNISToriginal with C-MNISToriginal+font to see if the addition of font data increased the accuracy. From the results in figure 6 we had to conclude that C-MNISToriginal+font has performance roughly equal to C-MNISToriginal at the ratios where C-MNISToriginal+GAN is more accurate. The addition of more font data cannot explain the additional accuracy of C-MNISToriginal+GAN indicating this increase is a property of the transformation made by the GAN.
Due to a limited amount of time, no finetuning has been done on the other hyperparameters of the GAN. Optimizing these hyperparameters might further improve classification accuracy which should result in a further reduction in the amount of required samples from the real dataset.
We measured the performance of C-MNISToriginal+GAN versus C-MNISToriginal. It showed that even though the generated samples are not good samples for their target class, C-MNISToriginal+GAN quickly becomes much more accurate than C-MNISToriginal before the samples look like useful samples. This effect can partially be explained by results shown by Rolnick et al. that indicate that deep learning is robust to massive label noise. This would mean that the network is still capable of learning higher level features from the mislabeled samples and is able to succesfully ignore the bad labeling.
Our goal was to use a GAN to close the distribution gap between rendered and real datasets.
Using MNIST as an example, we were able to show that it's possible to create a rendered dataset. We've shown that a distribution gap exists between the dataset we created and the real MNIST dataset and were able to close this gap using our described technique.
We've shown that GANs can be used to inflate trainingsets by reducing the gap between synthetic and real datasets. Furthermore, they can do so with very little real training data. This technique can be very useful for problems where only a small real dataset is available.